

Salesforce, Salesforce Clouds
Speed Is A Strategy, Not A Setting: How Mid-Market IT Should Move
July 08, 2026
Read Now.svg)

November 19, 2025
.svg)
.svg)


When Salesforce first released the Data Processing Engine (DPE), I’ll admit—I ignored it. At the time, I was working with Financial Services Cloud (FSC) and relying heavily on Roll-Up by Lookup (RBL) for account summaries. DPE seemed abstract and overly complex compared to the familiar RBL approach.
Years later, while helping a client migrate to FSC, I had to revisit DPE. What started as curiosity turned into one of the most valuable Salesforce learning experiences I’ve had. DPE turned out to be a powerful, scalable tool that bridges the gap between Flows and Apex, allowing admins to handle data transformations at scale—without writing a single line of code.
In this post, I’ll break down what DPE actually does, how it compares to RBL, the challenges I ran into, and the practical lessons I wish I had known sooner.
Salesforce defines DPE as:
“A metadata-driven visual tool that helps you create definitions using various nodes for different types of data transformations.”

At its core, DPE runs in three stages: define your data sources, transform the data, and write the results back.
That’s a mouthful, so here’s what it really means:
DPE essentially lets you build definitions — sets of data instructions that can run manually, on a schedule, or via automation (Flow, Apex, or API). In short, DPE is built for massive-scale data operations that would time out in Flow but don’t justify the complexity of Apex.
When FSC launched in 2016, it included Roll-Up by Lookup (RBL) to aggregate data from Financial Accounts to Households or Persons. It was handy, but limited. RBL only worked with the Financial Account object and couldn’t handle anything custom.
DPE, on the other hand, was built directly into the Salesforce platform, not as part of a managed package. That change unlocked far more power and flexibility. With DPE, you can roll up, join, or transform data across any object, even external data sources.
Think of it like this:
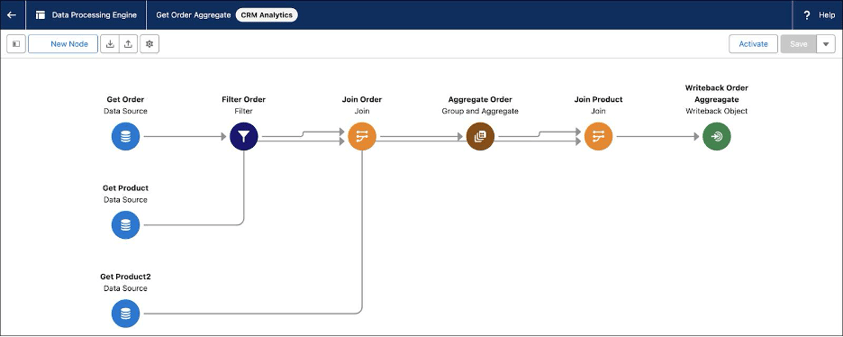
When I first implemented DPE, my client’s goal sounded simple: roll up financial data. The reality was more complex — data existed at multiple hierarchy levels and needed to roll up differently based on record types. Here’s how DPE handled each case:
Financial data lived in a custom object several levels below Account. We needed to aggregate these values up to the parent record.
Why DPE worked: RBL only supported Financial Account → Account roll-ups, but DPE can aggregate from any object
We had recurring financial transactions stored in a lower-level object. The requirement: create summarized “snapshot” records at each level in the hierarchy to report historical data.
Solution: DPE definitions generated new child summary records with aggregated data for each level
We needed to compare two data sets from the same source to identify which records were “Current” and which were “Historical.”
My favorite discovery: Using Join nodes, I could compare two versions of the same data — no Apex required
In one case, certain transactions needed to roll up to an Account without a direct relationship.
For example, if a transaction had “Company A” as a picklist value, it needed to aggregate under the Account record for “Company A”
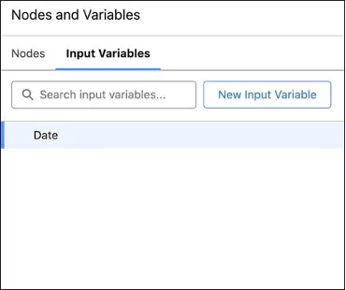
The trick? I created a DPE Definition with two input variables:
Instead of creating ten separate definitions for each company, I leveraged a scheduled Flow to call the same DPE Definition multiple times — once for each picklist/Account pair. Each run passed in a different set of variable values, much like how you’d reuse a subflow with different inputs.

Getting started with DPE wasn’t smooth. Even with years of Flow experience, the logic model is completely different. Here are the biggest lessons I learned:
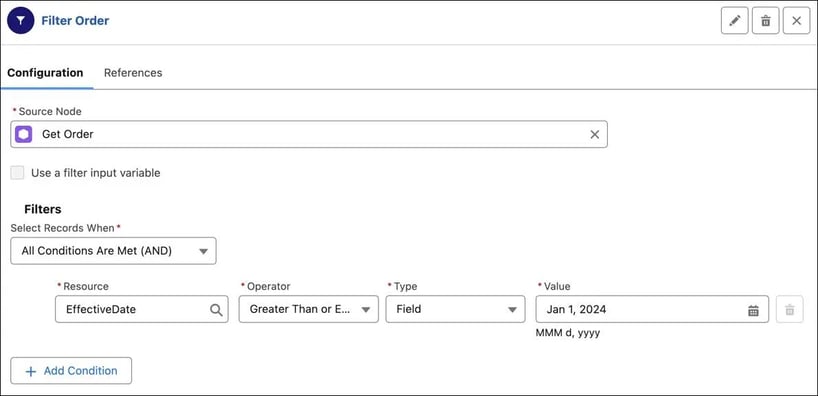
One of the first challenges I ran into with DPE was understanding how it determines the order of execution.
In Flow Builder, everything connects to a single Start node — you control exactly what runs and when. DPE works differently. Each Data Source node acts as its own starting point, and you must define all of them before building the rest of your Definition. Once you add more than one Data Source, you can’t dictate which one runs first — DPE decides.
You do, however, have two ways to influence sequence:
Because multiple Data Sources can exist in one Definition, you can also create parallel data flows that have no direct relation to each other. Whether you design one large, complex Definition or several smaller, modular ones is up to you — DPE will execute every branch you build.
Tip: Use Writeback node order values to define when each output executes.

Unlike Flow, the Data Processing Engine doesn’t support conditional paths or “if/else” logic. When a Definition runs, it executes every node in the process — no exceptions.
You can branch connections to perform multiple transformations in parallel, but those branches all run regardless of conditions.
If you need true conditional behavior (for example, only running certain definitions when criteria are met), handle that logic in the Flow or Apex that triggers the DPE Definition.
Data in DPE is represented as rows and columns, not as Objects. You can join completely different data sets without worrying about lookup relationships, but it also means you lose type-specific helpers.
You can freely drag and arrange nodes across the DPE canvas, just like in Flow, but don’t waste the effort. As soon as you save your Definition, DPE automatically resets the layout based on its own logic. Focus on function, not aesthetics.
Unlike Flow, the Data Processing Engine doesn’t offer a debug or rollback mode. When you run a Definition, it commits real changes to your data — no simulation or safety net.
Until Salesforce adds a rollback option, I recommend testing with filters that limit the number of records processed. This keeps it running faster, safer, and easier to troubleshoot.
DPE doesn’t include built-in version control like Flow does. You can use Save As to clone a Definition, but there’s no native version history or rollback.
To manage versions manually, clone and rename each iteration (e.g., DefinitionName_V1, V2, etc.). This simple habit is critical for complex builds — especially since the DPE builder can still be a bit buggy.
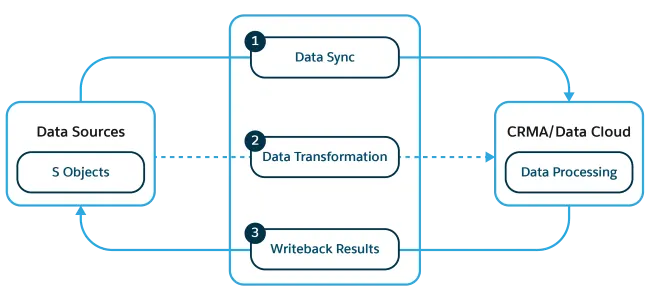
There’s no auto-trigger built into DPE, so you’ll need to call your definitions manually or through automation:
To make a Flow wait until the DPE run finishes, configure a Wait element that pauses until the workflow service completes.
Here are the issues I ran into — and what I’d do differently next time:
If you’re diving into DPE for the first time, here’s what I’d emphasize:
Sketch out your data flow. Know your source, transformations, and destinations before dropping your first node.
Clone before editing. DPE doesn’t track versions, and bugs can corrupt a Definition.
Break large data transformations into multiple smaller Definitions. It’s faster to test and easier to maintain.
Once you understand the pattern — Data Source → Transform → Writeback — you’ll start seeing endless possibilities.
The Data Processing Engine might look intimidating at first, but once you understand its structure, it becomes an admin’s secret weapon. It’s more powerful than Flow, less complex than Apex, and capable of handling data scenarios that used to be impossible without code.
If you’re in Financial Services Cloud — or any org with complex roll-up and aggregation needs — it’s worth the time investment. My first DPE project started as a simple roll-up request. It ended with ten Definitions and a new appreciation for how Salesforce continues to close the gap between clicks and code.


Salesforce, Salesforce Clouds
July 08, 2026
Read Now

Salesforce, Salesforce Clouds
July 07, 2026
Read Now

Salesforce, Salesforce Clouds
June 30, 2026
Read Now